Radix sort を実装 & 測定してみた
Radix sort とはソート対象(key)に対して、下の桁から順にソートを行うソートアルゴリズムの一種です。
例えば図のような数列があったとき、最初は一桁目を見てソートを行います。その次は二桁目を見て同様にソートし、これを最上位桁まで繰り返します。
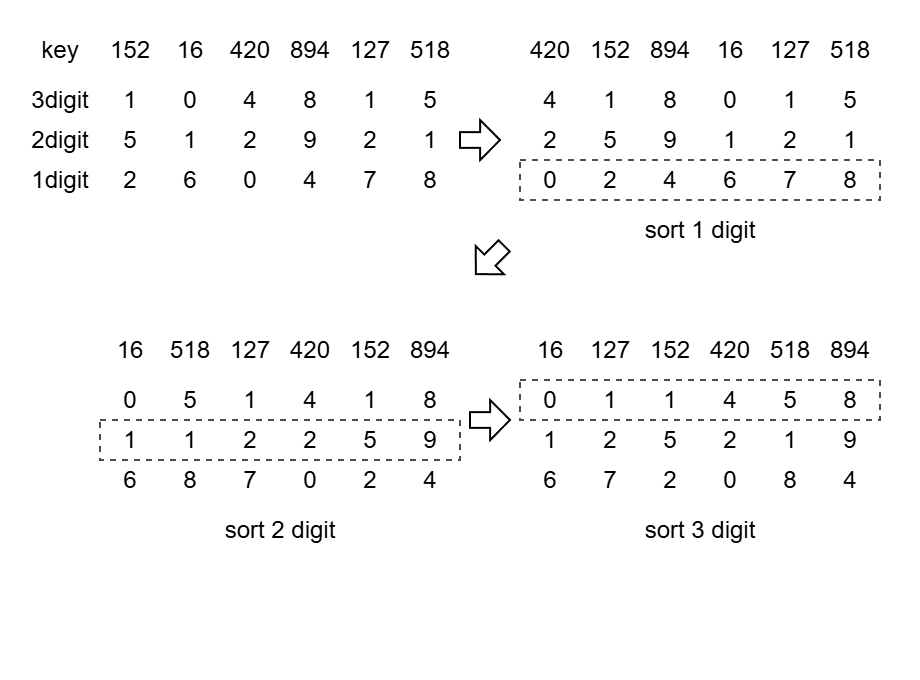
Radix sort の特徴としては安定ソート、比較が不要、並列化が可能なこと、計算量が要素数 $N$ と桁数 $k$ に対して $O(kN)$ が挙げられます。そのため、GPU driven のソートアルゴリズムとして扱われており、半透明オブジェクトのソートに使用されるなど、3DCG の分野でも活用されています。
本記事では、radix sort のアルゴリズムを解説するとともに、CPU および GPU 向けのシンプルな実装例と、その性能評価の結果を紹介します。
アルゴリズムの詳細
Radix sortは原理上いかなる進数でも可能ですが、応用上の理由から一般的に二進数を使用します。
二進数でもやることは変わりません。二進法で表された key に対して下から順に桁を抜き出して、その桁でソートすることを繰り返していきます。
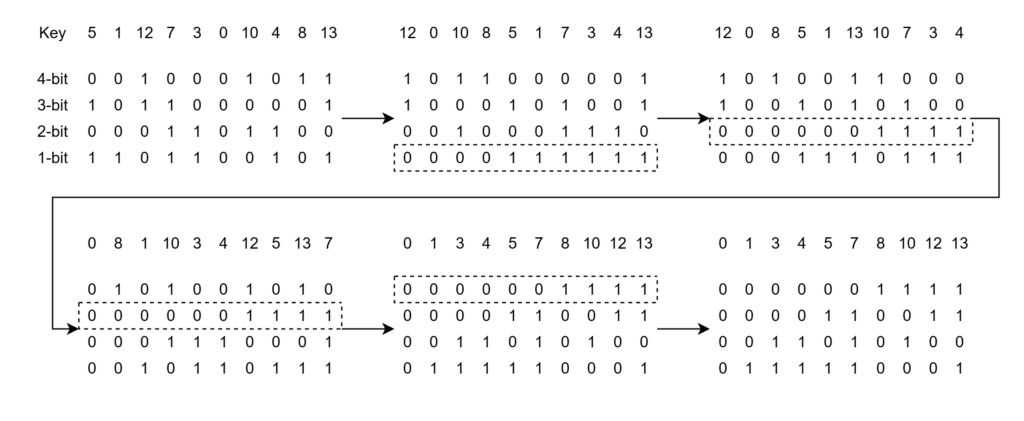
Radix sort は桁のソートに bucket sort を使用することで高速なソートを実現しています。
Bucket sortとは bucket というデータの置き場を key の種類だけ用意して、key をその種類に応じて bucket に分配するというソートです。最終的に前の bucket から要素を取り出していけばソートされた結果が出てきます。
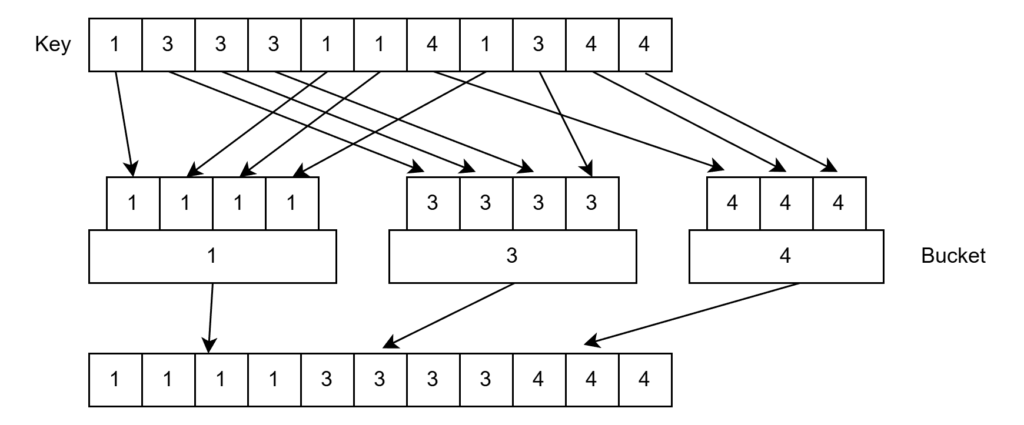
このソートの良い点は key の比較がいらず、要素数 $N$ に対して $\text{O}(N)$ と高速に行えることです。なかなかユニークな特徴ですが、致命的な弱点として基本的に bucket の数が膨大になるという点が挙げられます。
例えば uint の範囲で真正面から bucket sort する場合、1,2,3,…,10,…,1000,…とuint が取りうる値ごとにそれぞれ bucket を用意しなくてはいけません。ということはつまり、uint のソートになんと $2^{32}$ 個の bucket が必要になります。
このように bucket sort は汎用的なソートアルゴリズムではなく、key の種類(= bucket の数)がごく小さい条件下でのみ使用できる限定的なアルゴリズムとして扱われます。
Radix sort はこの性質をうまく活用します。桁のソートでは対象となる key は二進数のため 0, 1のたった二つです(これが二進法を採用している理由です)。従って、2つの bucket によって bucket sort が行えるようになっています。
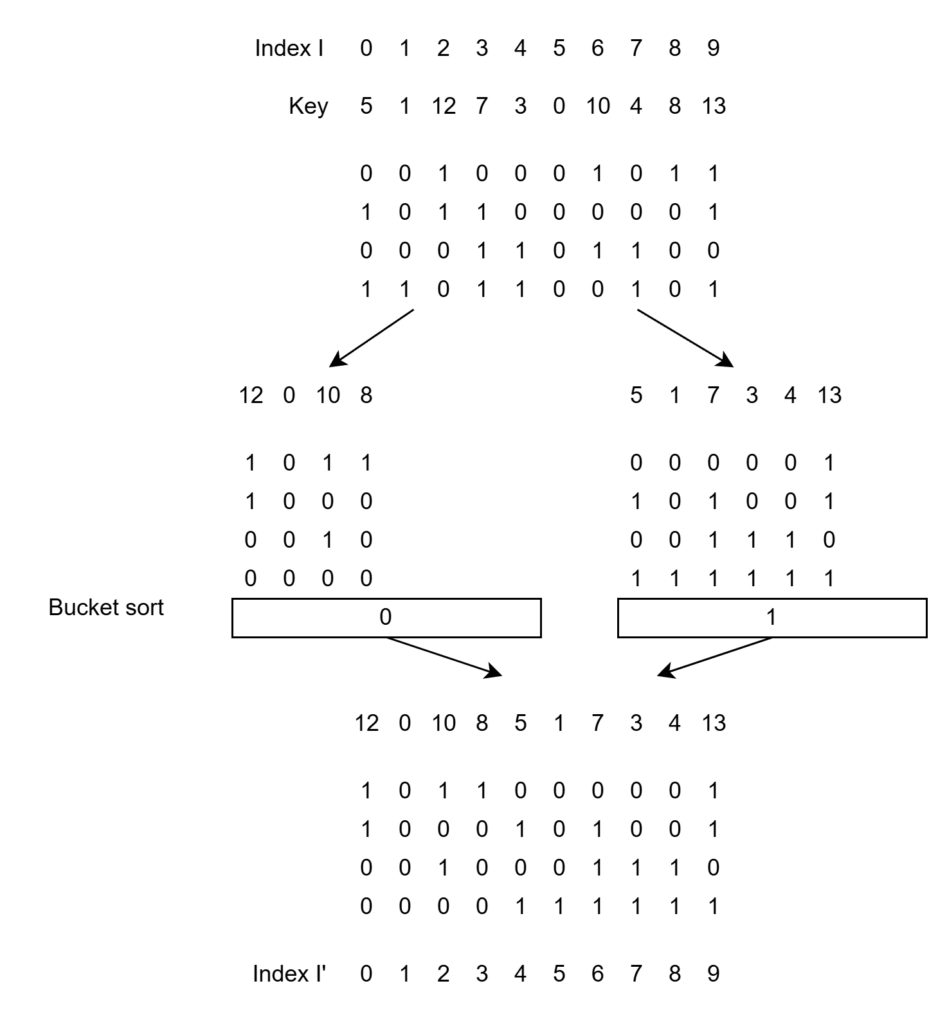
また、bucket 数の少なさからソート後の index を容易に求められます。インデックス $i$ の key $k_i$に対して、$i$ より前にある 0 の key の数を $s_i$, 全体の 0 の key の数を $F$、key の総数を $n$ とすると、ソート後のインデックス $i’$ は次のように表せます。
$$
i’ =
\begin{cases}
s_i & (k_i = 0) \\
n – s_i + F & (k_i = 1)
\end{cases}
$$
これの導出は bucket sort の流れを見ればわかります。0の key の場合、bucket には既に $f_i$ 個の key が積まれており、それがそのまま最終的に吐き出されるので index は $s_i$ となります
反対に1の場合は、1の bucket に積まれている数は総数$(i+1)$から0の分 $s_n$ を引いた $i -s_n$ です。そして最後整列されるとき、0の後に置かれるので、0全体の数 $F$ を知っていれば $F+i -s_i$ となることがわかります。
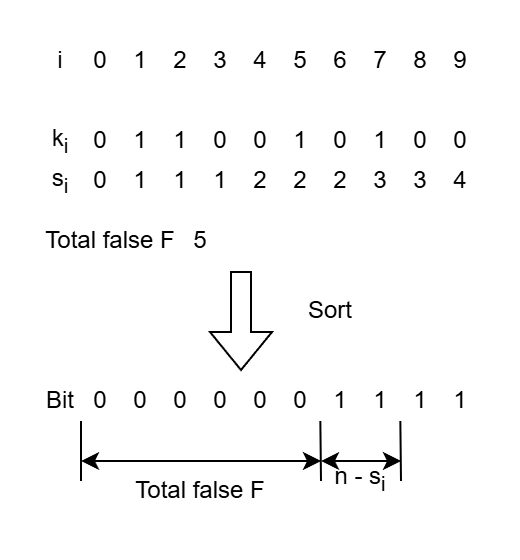
$s_i$ と $F$ の2つさえ分かれば要素ごと独立してソートができます。$s_i$ に関しては 0の bit の累積和を取れば求まりますし、$F$ も最後の $s_N$(と最後の key)から求まります。累積和の並列アルゴリズムは既にありますので、radix sort もそのまま並列化することが可能となります。
符号付型、浮動小数点型に対する radix sort
Radix sort はそのアルゴリズム上、ビット列の順序(= uint の順序)と実際に表現される数値の順序が一致していないと期待する結果が得られません。
わかりやすい例としては int 型で、int 型の数値を radix sort にかけると符号部が最上位ビットのため負の値が降順で出てきて、その後昇順で正の値が並ぶ結果が帰ってきます。float 型も同様の結果を導きます。
このため、int 型や float 型などの radix sort では直接その値を使うのではなく、期待する順序になるような uint の key へと変換する必要があります。
int 型の変換には次のような性質が要求されます
- 負の値同士ならば数値部が高い方が前になる
- 正の値同士ならば数値部が低い方が前になる
- 符号が異なるならば、負の値が前になる
これに基づくと、int 型の変換は次のようなアルゴリズムで書くことができます(C++ 実装)。
inline uint32_t IntToOrderedUint(int value)
{
uint32_t key;
memcpy(&key, &value, sizeof(float));
if (key & 0x80000000)
{
// negative value
return ~key;
}
else
{
// positive value
return key ^ 0x80000000;
}
}
- 符号部が 1 ならばビット反転
- 符号部が 0 ならば最上位ビットを 1 に設定
float 型は符号を除けば、数値とビット列の順序は一致していることが知られています(Appendix に簡単な証明を載せました)。なので float 型も int 型と同様のアルゴリズムで変換することができます。
ただし、浮動小数点には NaN や Inf といった特殊な値があり、これに関しては例外処理を入れるのがベターだと思います。
inline uint32_t FloatToOrderedUint(float value)
{
uint32_t key;
memcpy(&key, &value, sizeof(float));
if (std::isinf(value) || std::isnan(value))
{
return 0xFFFFFFFF; // as a maximum
}
if (key & 0x80000000)
{
// negative value
return ~key;
}
else
{
// positive value
return key ^ 0x80000000;
}
}
どう処理するかは設計思想によると思います。例として、ここでは一番後ろになるように最大値として扱っています。
以上が int 型と float 型の radix sort のやり方になります。ここでは 32 bit 型を例にしましたが、16 bit でも 64 bit 型でも同様の手順で行うことができます。
実装
今回は float に対する radix sort を CPU と GPU 両方で実装してみました。言語は C++, GPU側の実装は Vulkan と Slang を使用しています。この実装は分かりやすさを重視しています。
CPU 実装はこちらのようになっています。$s_i$ の計算は累積和が inclusive か exclusive かで参照するインデックスが異なるので注意してください。今回の実装は inclusive scan による累積和を実装しています。
std::vector<float> CpuRadixSort(const std::vector<float>& initialKeys)
{
size_t numKey = initialKeys.size();
std::vector<float> keyInput = initialKeys;
std::vector<float> keyOutput(numKey);
std::vector<int> prefixSum(numKey);
for (int i = 0; i < 32; i++)
{
// inclusive scan
for (int j = 0; j < numKey; j++)
{
uint32_t key = FloatToOrderedUint(keyInput[j]);
bool bit = (key >> i) & 0x01;
if (j == 0)
{
prefixSum[j] = !bit;
}
else
{
prefixSum[j] = prefixSum[j - 1] + !bit;
}
}
// bucket sort
for (int j = 0; j < numKey; j++)
{
uint32_t si;
if (j == 0)
si = 0;
else
si = prefixSum[j - 1];
uint32_t totalFalse = prefixSum.back();
// exclusive prefix sum version
// si = prefixSum[j];
// uint32_t finalKey = FloatToOrderedUint(keyInput.back());
// bool finalBit = (key >> i) & 0x01;
// totalFalse = prefixSum.back() + finalBit;
uint32_t key = FloatToOrderedUint(keyInput[j]);
bool bit = (key >> i) & 0x01;
uint32_t nextIndex = (!bit) ? si : j - si + totalFalse;
keyOutput[nextIndex] = keyInput[j];
}
std::swap(keyInput, keyOutput);
}
return std::move(keyInput);
}
GPU 実装については prefix sum と bucket sort の compute shader は次のようになっています。ダブルバッファリングを前提として、push constant を通して入力と出力のバッファを切り替えています。また、累積和は naive parallel scan によって実装しています(詳細は GPU Gems 3 の記事をご参照ください)
// prefix_sum.slang
struct PrefixSumSettings
{
uint32_t numKey;
uint32_t keyInputId;
uint32_t prefixSumInputId;
uint32_t prefixSumOutputId;
uint32_t prefixSumCount;
uint32_t sortCount;
};
[vk_push_constant]
PrefixSumSettings constant;
[vk_binding(0, 0)]
RWStructuredBuffer<float> keys[2];
[vk_binding(1, 0)]
RWStructuredBuffer<uint32_t> prefixSum[2];
uint32_t FloatToOrderedUint(float value)
{
if (isnan(value) | isinf(value))
{
return 0xFFFFFFFF; // as a maximum
}
uint32_t key = reinterpret<uint32_t>(value);
if (bool(key & 0x80000000))
{
// negative value
return ~key;
}
else
{
// positive value
return key ^ 0x80000000;
}
}
inline bool GetBit(uint32_t index)
{
return bool(FloatToOrderedUint(keys[constant.keyInputId][index]) & (1u << constant.sortCount));
}
uint32_t Pow2(int n)
{
return 1u << n;
}
// naive scan ( inclusive scan )
[shader("compute")]
[numthreads(32, 1, 1)]
void CSMain(uint3 threadId: SV_DispatchThreadID)
{
let index = threadId.x;
if (index > constant.numKey) return;
// initialize
if (constant.prefixSumCount == 0)
{
prefixSum[constant.prefixSumOutputId][index] = !GetBit(index);
return;
}
let input = prefixSum[constant.prefixSumInputId];
let output = prefixSum[constant.prefixSumOutputId];
int offset = Pow2(constant.prefixSumCount - 1);
int targetIndex = index - offset;
if (targetIndex >= 0) output[index] = input[index] + input[targetIndex];
else output[index] = input[index];
}
// bucket_sort.slang
struct SortSettings
{
uint32_t numKey;
uint32_t keyInputId;
uint32_t keyOutputId;
uint32_t prefixSumOutputId;
uint32_t sortCount;
};
[vk_push_constant]
SortSettings constant;
[vk_binding(0, 0)]
RWStructuredBuffer<float> keys[2];
[vk_binding(1, 0)]
RWStructuredBuffer<uint32_t> prefixSum[2];
uint32_t FloatToOrderedUint(float value)
{
if (isnan(value) | isinf(value))
{
return 0xFFFFFFFF; // as a maximum
}
uint32_t key = reinterpret<uint32_t>(value);
if (bool(key & 0x80000000))
{
// negative value
return ~key;
}
else
{
// positive value
return key ^ 0x80000000;
}
}
[shader("compute")]
[numthreads(32, 1, 1)]
void CSMain(uint3 threadId: SV_DispatchThreadID)
{
let index = threadId.x;
if (index > constant.numKey) return;
let input = keys[constant.keyInputId];
let output = keys[constant.keyOutputId];
let endIndex = constant.numKey - 1;
uint32_t totalFalse = prefixSum[constant.prefixSumOutputId][endIndex]; // for inclusive prefix sum
let si = (index == 0) ? 0 : prefixSum[constant.prefixSumOutputId][index - 1]; // for inclusive prefix sum
uint32_t targetBitMask = 1u << (constant.sortCount);
uint32_t key = FloatToOrderedUint(input[index]);
bool targetBit = bool(key & targetBitMask);
uint32_t nextIndex = targetBit ? index - si + totalFalse : si;
output[nextIndex] = input[index];
}
Vulkan 側の処理は少々コード量が多いので、radix sort にだけ関わるコマンドかつ一部疑似コードで掲載します。
// Vulkan implementation
CommandBuffer cmd;
uint32_t numKey = initialKey.size();
uint32_t iterator = std::bit_width(numKey);
for (int i = 0; i < 32; i++)
{
for (int j = 0; j < iterator; j++)
{
PrefixSumSettings prefixSumSettings;
prefixSumSettings.numKey = numKey;
prefixSumSettings.keyInputId = i % 2;
prefixSumSettings.prefixSumInputId = j % 2;
prefixSumSettings.prefixSumOutputId = (j + 1) % 2;
prefixSumSettings.prefixSumCount = j;
prefixSumSettings.sortCount = i;
PushConstant pc;
pc.data = &prefixSumSettings;
pc.offset = 0;
pc.size = sizeof(PrefixSumSettings);
pc.stages = ShaderStage::Compute;
cmd->BindPipeline(prefixSumPipeline);
cmd->BindDescriptorSet(descSet);
cmd->BindPushConstant(pc);
cmd->Dispatch(std::ceil(numKey / 32), 1, 1);
cmd->Barrier(prefixSumBuffers[0]);
cmd->Barrier(prefixSumBuffers[1]);
}
SortSettings settings;
settings.numKey = numKey;
settings.keyInputId = i % 2;
settings.keyOutputId = (i + 1) % 2;
settings.prefixSumOutputId = iterator % 2;
settings.sortCount = i;
cmd->BindPipeline(bucketSortPipeline);
PushConstant pc;
pc.data = &settings;
pc.offset = 0;
pc.size = sizeof(SortSettings);
pc.stages = ShaderStage::Compute;
cmd->BindPushConstant(pc);
cmd->BindDescriptorSet(descSet);
cmd->Dispatch(std::ceil(numKey / 32), 1, 1);
cmd->Barrier(keyBuffer[0]);
cmd->Barrier(keyBuffer[1]);
}
測定
$10^8$ 個の key におけるソート時間を測定してみました。今回の CPU 実装と GPU 実装に加えて、比較対象として std::sort(MSVC 19.36, C++ 20) の結果も記載しています。CPU 環境は Intel Core i7-13700, GPU 環境は NVIDIA GeForce RTX 4070 を使用しています。
最適化していないので CPU 実装はかなり遅いですが、GPU 実装は std::sort より 3 倍程度高速であることが確認できました。並列化の強さがよくわかります。
| Radix sort(CPU) | Radix sort(GPU) | std::sort |
| 42.14 sec | 2.43041 sec | 8.5107 sec |
終わりに
Radix sort は学んでみると、意外とアルゴリズム自体はとてもシンプルですし、bucket sort による高速化や並列化はいい発想で面白いと感じました。
一方で、並列化そのものには累積和やインデックスの計算などやや複雑な要素があるので、GPU 実装はそこそこコストがかかりました。インデックスが1ずれてるとか細かいミスでも結果が破壊されてしまうので、結構デバッグが大変です(GPU デバッグの難しさも相まって)。
とはいえ、実装してみると中々に高速でやりがいを感じます。実際の事例でも爆速で動いてくれてとても楽しかったです。
Reference
- @tommyecguitar. GPU最速ソート! Radix Sort その①.
- Takahiro Harada and Lee Howes. Introduction to GPU Radix Sort.
- GPU Gems 3. Chapter 39. Parallel Prefix Sum (Scan) with CUDA.
Appendix : 浮動小数点型の順序
IEEE 754 によって定義される単精度浮動小数点 (float) は下位 23 bit を仮数部、8 bit を指数部、最上位ビットを符号部としています。
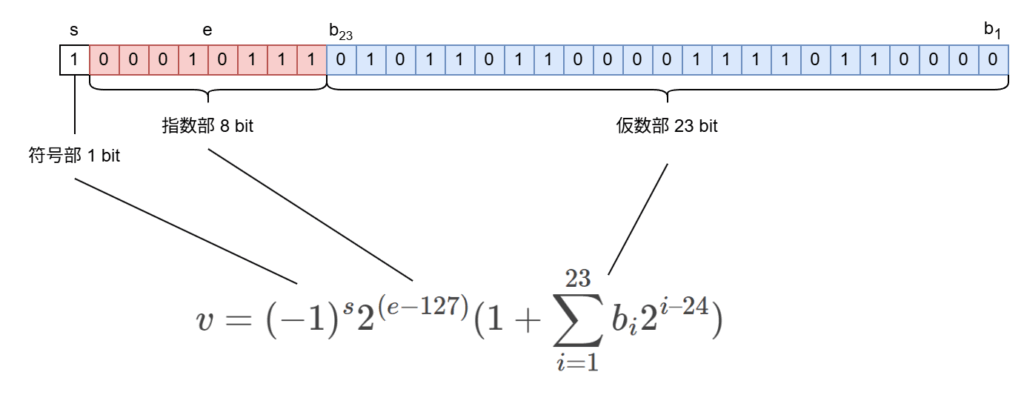
float が表す数値 $v$ は $i$ 番目のビットを $b_i$ 、指数部が表す整数値を $e$ 、符号ビットを $s$ とすると以下のように定義されています。
$$
v = (-1)^s 2^{(e-127)} (1 + \sum_{i=1}^{23} b_i 2^{i – 24})
$$
今回の話では符号部を取り除いた float の表現値 $v$
$$
v = 2^{(e-127)} (1 + \sum_{i=1}^{23} b_i 2^{i – 24})
$$
と、そのビット列を符号なし整数と解釈した値 $I$
$$
I = \sum_{i=1}^{31} b_i 2^{i}
$$
に関してどちらの表現を使っても大小関係が変わらないことを示します。2つの float 値 $(v_1, I_1), (v_2, I_2)$ に対して、以下の同値関係を導けば良さそうです。
$$
v_1 < v_2 \Leftrightarrow I_1 < I_2
$$
大小関係が分かりやすいように、仮数部の表現に二進法小数を使うことにします。仮数部は二進法小数に書き直すと
$$
{1.b_{32}b_{31} … b_1}_{(2)}
$$
という値を意味しています。例えば、$1000….0$ という仮数部は $1.1000…0_{(2)}$ という二進法小数を表しています。
ここでは小数部を$M$と置いて
$$
1.M_{(2)} \equiv {1.b_{32}b_{31} … b_1}_{(2)}
$$
と書くことにします。
$$
v = 2^{(e-127)} \times 1.M_{(2)}
$$
$I_1 < I_2 \Rightarrow v_1 < v_2 $について考えてみます。ここでは一気にやるのは難しそうなので $I_1 < I_2$ を 2 つの場合に分けて評価してみます。
- 指数部が同じで、仮数部が異なる $e_1 = e_2, M_1 < M_2 \Rightarrow v_1 < v_2$
- 指数部が異なる $e_1 < e_2 \Rightarrow v_1 < v_2$
$e, M$ はそれぞれ $I$ をほぼそのまま抜き出した形式であるので、場合分けとしては恐らく適切なはずです。
1 に関しては簡単です。$1.M_{2}$ という二進法小数は単に $M$ をシフトさせただけのものですので、
$$
{1.M_1}_{(2)} < {1.M_2}_{(2)}
$$
が成り立ちます。すなわち、同じ指数部 $e = e_1 = e_2$ を持つなら
$$
2^{(e-127)} \times {1.M_1}_{(2)} < 2^{(e-127)} \times {1.M_2}_{(2)} \Leftrightarrow v_1 < v_2
$$
となります。
2 に関しては数学的帰納法から求められそうです。$e_2 = e_1 + 1$ として、指数が大きければ仮数部がどうであれ $v_1 < v_2$ が成り立つことを示してみます。
ある指数 $e$ に対する最大値$v_{e, \text{max}}$、最小値$v_{e, \text{min}}$はそれぞれ仮数部が全て1、0 であるときの値です。具体的には以下のように書くことができます。
$$
v_{e, \text{max}} = 2^{(e-127)} (1 + \sum_{i=1}^{23} 2^{i – 24})
$$
$$
v_{e, \text{min}} = 2^{(e-127)}
$$
ここで、$e_1$ における最大値と $e_1 + 1$ における最小値を比較してみると
$$
(1 + \sum_{i=1}^{23} 2^{i – 24}) 2^{(e_1-127)} < 2^{(e_1 + 1 -127)}
$$
が成り立ちます。$2^{(e_1 -127)}$ で割ってみると分かりやすいです。 $\sum_{i=1}^{23} 2^{i – 24}$は小数部なので $\sum_{i=1}^{23} 2^{i – 24} < 1$ であることを鑑みれば、確かに正しい不等式であることが分かります。
$$
1 + \sum_{i=1}^{23} 2^{i – 24} < 2
$$
$e_1 = 0$ でも成り立つので、任意の指数部において、どのような仮数部であったとしても大きい指数部を持つ方が数値として大きいことを意味しています 。したがって、$e_1 < e_2 \Rightarrow v_1 < v_2$であることが分かりました。
こうして、$I_1 < I_2 \Rightarrow v_1 < v_2$ の証明ができました。もともと、$I$ と $v$ は 1 対 1 関係にあるので、$v_1 < v_2 \Leftarrow I_1 < I_2 $も同様の議論をすることができます。
少々、冗長な証明になってしまいましたが、これで少なくとも float は int と同じ比較処理によって大小関係を定義できることが分かりました(ただし、実装上は NaN, Inf を例外とする必要があります)。


