輪郭線をPostProcessで描画する
はじめに
備忘録と復習を兼ねて、PostProcessで輪郭線を描画してみました。
本記事では、PostProcessで輪郭線を描画した際に使用した技法について、簡潔に解説をしていきます。
開発環境
Unity 2020.2.3f1を用いて開発を行っています。
エッジの検出手法
今回、画像からエッジを検出する手法として、RobertsCrossとSobelFilterを使用しました。下に二つの手法の簡単な説明を載せておきます。
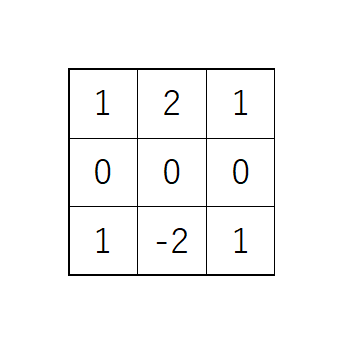
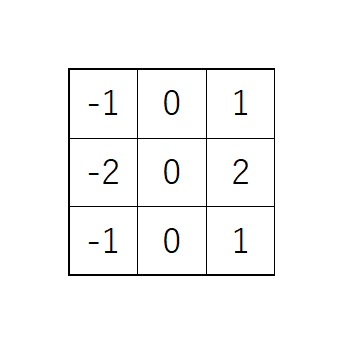
SobelFilter
SobelFilterはノイズを減らすための平滑化処理とエッジ抽出処理をひとまとめにして行う手法で、下図のような縦線検出と横線検出の2つのオペレータを用います。
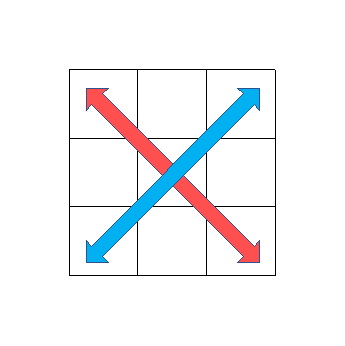
RobertsCross
SobelFilterとは違い、下図のように斜め方向に差分を計算してエッジを抽出する手法です。
深度情報から輪郭線を抽出
手始めにRobaertsCrossを使用して深度バッファからエッジを検出して輪郭線を描画してみます。下にシェーダコードを載せておきます。
float halfScaleFloor = floor(_SampleScale * 0.5f); float halfScaleCeil = ceil(_SampleScale * 0.5f); float2 uv0 = i.texcoord - float2(_MainTex_TexelSize.x, _MainTex_TexelSize.y) * halfScaleFloor; float2 uv1 = i.texcoord + float2(_MainTex_TexelSize.x, _MainTex_TexelSize.y) * halfScaleCeil; float2 uv2 = i.texcoord + float2(_MainTex_TexelSize.x * halfScaleCeil, -_MainTex_TexelSize.y * halfScaleFloor); float2 uv3 = i.texcoord + float2(-_MainTex_TexelSize.x * halfScaleFloor, _MainTex_TexelSize.y * halfScaleCeil); float centerDepth = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord); float d0 = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, uv0).r; float d1 = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, uv1).r; float d2 = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, uv2).r; float d3 = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, uv3).r; float d10 = d1 - d0; float d32 = d3 - d2; float edgeDepth = sqrt(d10 * d10 + d32 * d32); depthEdge = edgeDepth > _DepthThreshold * centerDepth ? 1.0f : 0.0f;
各行で何をやっているかについて説明します。
1~13行にかけて、_SampleScaleに基づいてサンプリングするUVのオフセット値を求めて、深度バッファから深度値をサンプリングしています。
15~17行では、RobertsCross演算を行っており、注目画素におけるエッジの強さを算出しています。
19行では、17行目で算出した値に対して閾値で制限をかけて、ノイズが誤ってエッジ検出されることを防いでいます。ここで閾値に注目画素の深度値を乗算しているのは、遠方でのエッジ検出ではより小さな差分が必要になるためです。閾値を変調して遠方でエッジ検出がうまくいくようにしています。
SobelFilterでも同じように深度バッファからエッジを抽出してみます。
float4 depthDiag; float4 depthAxis; float2 uvDist = _MainTex_TexelSize.xy * _SampleScale; float centerDepth = (SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord)); // Center depthDiag.x = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy + uvDist); // TR depthDiag.y = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy + uvDist * float2(-1.0f, 1.0f)); // TL depthDiag.z = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy - uvDist * float2(-1.0f, 1.0f)); // BR depthDiag.w = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy - uvDist); // BL depthAxis.x = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy + uvDist * float2(0.0f, 1.0f)); // T depthAxis.y = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy - uvDist * float2(1.0f, 0.0f)); // L depthAxis.z = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy + uvDist * float2(1.0f, 0.0f)); // R depthAxis.w = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.texcoord.xy - uvDist * float2(0.0f, 1.0f)); // B const float4 vertDiagCoeff = float4(-1.0f, -1.0f, 1.0f, 1.0f); //TR , TL , BR , BL const float4 horizDiagCoeff = float4(1.0f, -1.0f, 1.0f,-1.0f); const float4 vertAxisCoeff = float4(-2.0f, 0.0f, 0.0f, 2.0f); // T, L , R , B const float4 horizAxisCoeff = float4(0.0f, -2.0f, 2.0f, 0.0f); float4 sobelH = depthDiag * horizDiagCoeff + depthAxis * horizAxisCoeff; float4 sobelV = depthDiag * vertDiagCoeff + depthAxis * vertAxisCoeff; float sobelX = dot(SobelH, float4(1.0f, 1.0f, 1.0f, 1.0f)); float sobelY = dot(SobelV, float4(1.0f, 1.0f, 1.0f, 1.0f)); float sobel = sqrt(sobelX * sobelX + sobelY * sobelY); depthEdge = Sobel > _DepthThreshold * centerDepth ? 1.0f : 0.0f;
SobelFilterもやっていることはRobertsCrossとあまり大差ありませんが、サンプルする回数が多いです。
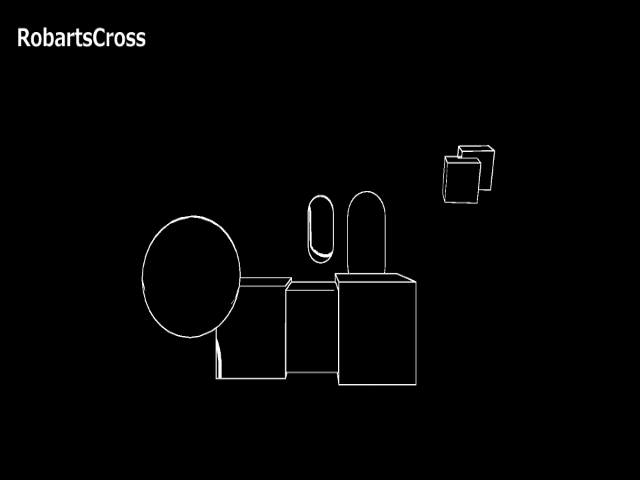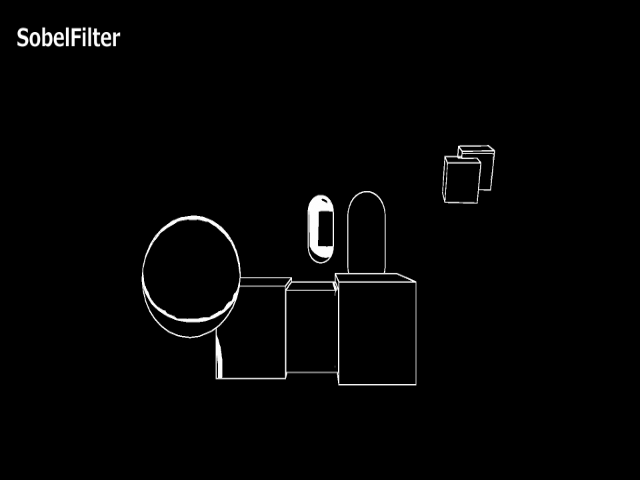
描画結果を見比べてみます。
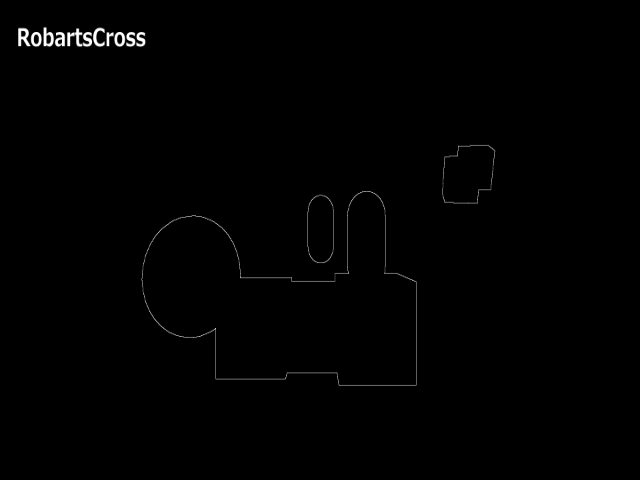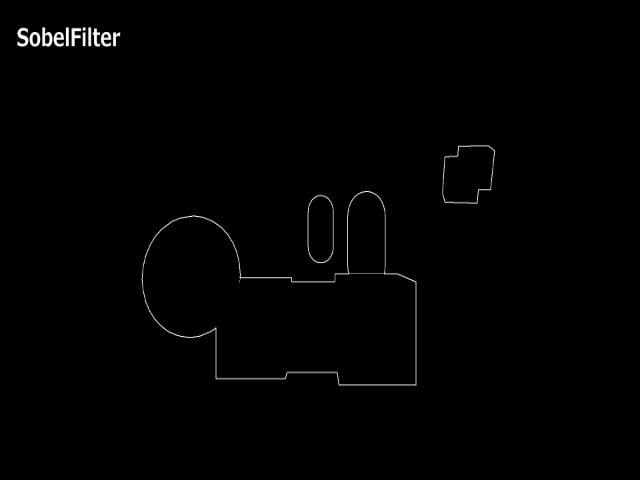
あまり見た目に大差はありませんが、RobertsCrossに比べてSobelFilterがのほうが太く出ていることがわかります。
ビュー法線情報からエッジ検出
基本的に深度バッファからエッジを検出するのとやることは変わらないので、コードは割愛します。
結果だけ見比べてみます。
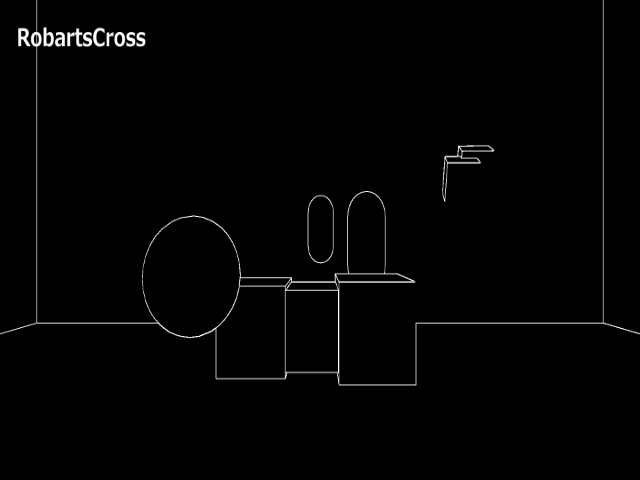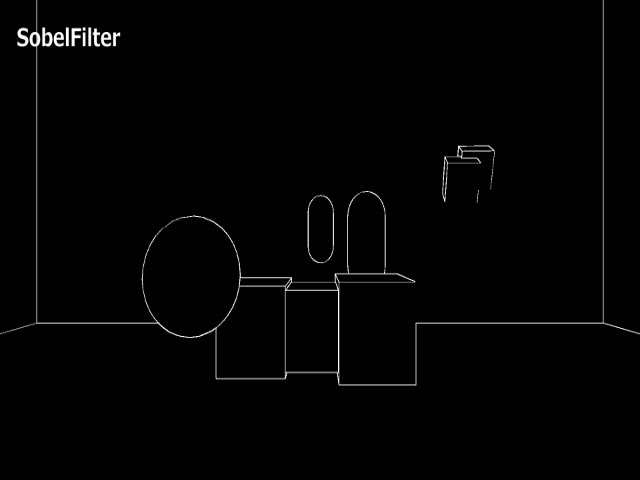
深度バッファを用いてエッジ検出したものと見比べてほしいのですが、法線を使ってエッジ検出をすることで、深度を使ったものより詳細なエッジを検出できていることがこの結果からわかります。立方体の角がわかりやすいかと思います。
色情報からエッジを検出してみる
これもコードは割愛します。まず下図のようなシーンのレンダリング結果があるとして、これを入力とし、RGBA情報のR成分に注目してエッジ検出を行ってみます。本来であれば、線の厚さ等をコントロールするバッファを用意することになると思いますが、今回は色があれば何でもいいので一旦レンダリング結果をそのまま使うことにしました。

下図のような結果となりました。
上記結果を見てわかる通り、愚直にシーンのレンダリング結果からエッジを検出しようとすると、エッジを検出してほしくないところまで検出処理が走ってしまうので工夫が必要のようです。今回は「別のバッファにエッジコントロール専用のデータを書き出して、ポストプロセス処理で入力として使用する」といった凝ったことはせずに、レンダリング結果をそのまま使えるように、ジオメトリを描画するシェーダーをデフォルトのものから、下記のようなライティング処理を行わずマテリアルカラーをそのまま出力するシェーダーに変えるようにしてみます。
Shader "Custom/UnlitShader"
{
Properties
{
_Color("Color", Color) = (1,1,1,1)
}
CGINCLUDE
#include "UnityCG.cginc"
ENDCG
SubShader
{
Tags { "RenderType" = "Opaque" }
LOD 200
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
struct appdata
{
float4 vertex : POSITION;
float3 normal : NORMAL;
float4 uv : TEXCOORD0;
};
struct v2f
{
float4 vertex : SV_POSITION;
float3 normal : NORMAL;
};
float4 _Color;
v2f vert(appdata v)
{
v2f o = (v2f)0;
o.vertex = UnityObjectToClipPos(v.vertex);
o.normal = UnityObjectToWorldNormal(v.normal);
return o;
}
float4 frag(v2f i) : SV_Target
{
float4 color = _Color;
return color;
}
ENDCG
}//pass
}//sub shader
FallBack "Diffuse"
}
上記のシェーダーコードでレンダリングした結果が下記になります。

そして、上記を入力として再度エッジ検出をかけた結果が下記になります。
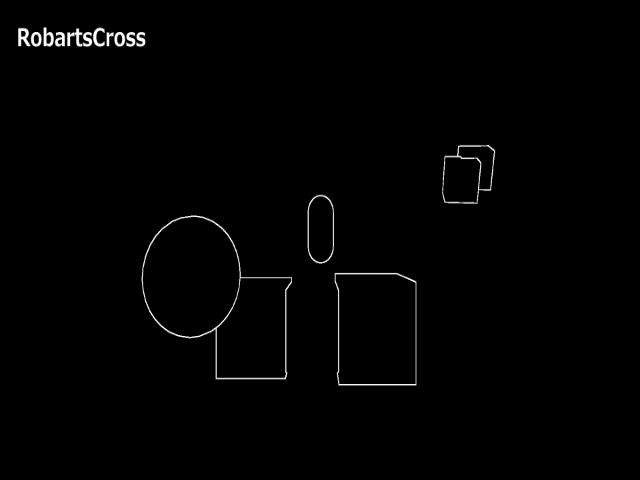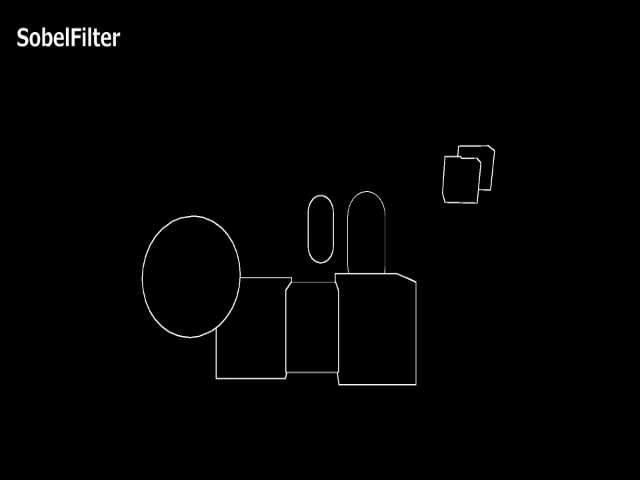
それぞれのバッファを合成してみる
最後に、それぞれのバッファからエッジを検出した結果をレンダリング結果と合成して出力します。

エッジの色はマゼンタで描画しています。
終わりに
RobertsCrossとSobleFilterで結果を比較しながら進めてみたわけですが、あまり差異がないように見えました。RobertsCrossの方がサンプル数が少ない分、負荷が軽そうです。ComputeShaderを使わずPixelShaderでポストプロセスを行いましたが、ComputeShaderを使えばPixelShaderより負荷が軽いものを作れそうです。
もし次に記事を書く機会があるとすれば、NPR系Shaderについて何か書こうと思っています。


